Кластер — это определенное количество серверов, объединенных в группу и образующих единый ресурс. Данное решение позволяет повысить надёжность, доступность и производительность системы и предназначено для исключения простоев в её работе.
Платформа Arta Synergy использует хранилище Cassandra и индексатор Elasticsearch, позволяющие создавать кластеры как для распределения нагрузки, так и для сохранения доступности данных.
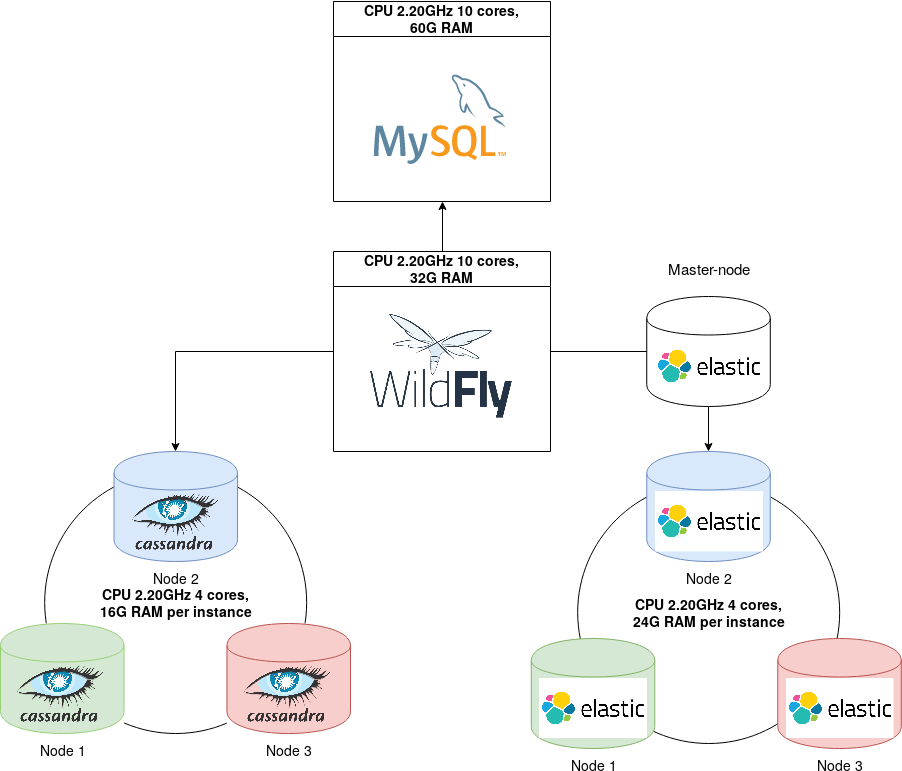
В данной инструкции приведены минимальные настройки следующей конфигурации:
платформа Arta Synergy
MySQL на отдельном сервере
главный узел (master-node) Elasticsearch на отдельном сервере
3 отдельных сервера, на каждом из которых установлены Cassandra и Elasticsearch
Примечание
На всех серверах время должно быть синхронизировано.
На сервере Synergy для MySQL нужно указать пути к БД в конфигурационном
файле standalone-onesynergy.xml, а также
логин и пароль пользователя с доступом к MySQL, если они отличаются от
установленных по умолчанию:
<xa-datasource jndi-name="java:/SynergyDS" pool-name="synergy_ds" enabled="true" use-ccm="fals$
<xa-datasource-property name="URL">
--> jdbc:mysql://192.168.2.3:3306/synergy?useUnicode=true&characterEncoding=utf8
</xa-datasource-property>
<driver>com.mysql</driver>
<xa-pool>
<min-pool-size>20</min-pool-size>
<max-pool-size>400</max-pool-size>
<is-same-rm-override>false</is-same-rm-override>
<interleaving>false</interleaving>
<pad-xid>false</pad-xid>
<wrap-xa-resource>false</wrap-xa-resource>
</xa-pool>
<security>
--> <user-name>root</user-name>
--> <password>root</password>
</security>
...
</xa-datasource>
Аналогично для StorageDS, для версий Arta
Synergy ниже 4.1 - jbpm.
В нашем примере сервер MySQL имеет ip-адрес 192.168.2.3 и стандартные учётные данные пользователя. Для применения изменений Wildfly/ JBoss должен быть перезапущен.
Затем на сервере MySQL нужно дать все права пользователю, который будет подключаться с сервера Synergy:
mysql> GRANT ALL PRIVILEGES ON *.* TO
'root'@'ip-адрес_сервера_Synergy' WITH GRANT OPTION IDENTIFIED BY
'root';
mysql> FLUSH PRIVILEGES;
Проверить подключение с сервера Synergy можно так:
# mysql -u {username} -p'{password}' -h {remote
server ip or name} -P {port} -D {DB name}
В нашем случае:
# mysql -uroot -proot -h 192.168.2.3 -P 3306 -D
synergy
В рассматриваемой конфигурации используется один главный узел и 3 узла с данными Elasticsearch. Главный узел в примере не хранит данные и используется только для извлечения данных и группирования результатов.
Настройки на сервере Synergy осуществляются в файле /opt/synergy/jboss/standalone/configuration/arta/elasticConfiguration.xml,
где нужно указать ip-адрес главного узла:
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<configuration xmlns="http://www.arta.kz/xml/ns/ai"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.arta.kz/xml/ns/ai http://www.arta.kz/xml/ns/ai/index.xsd">
<!-- URL доступа к серверу Elasticsearch -->
<url>http://192.168.2.111:9200/</url>
...
</configuration>
Также следует убедиться, что в нужных конфигурационных файлах (fileIndex.xml, docIndex.xml, formIndex.xml) индексатором установлен
Elasticsearch. Для применения изменений Wildfly/ JBoss должен быть
перезапущен.
На сервере главного узла в файле /etc/elasticsearch/elasticsearch.yml нужно
раскомментировать либо добавить следующие параметры:
cluster.name: elastic_cluster - имя
кластера, указывается на всех нодах кластера;
node.name: elastic_master - имя данного
узла;
network.host: 192.168.2.111 - указать
ip-адрес узла;
discovery.zen.ping.unicast.hosts: ["192.168.4.0",
"192.168.0.155", "192.168.2.158", "192.168.2.111"] - перечислить
ip-адреса всех нод кластера;
discovery.zen.minimum_master_nodes: 1 -
число серверов объединения процессов, требуемых для кворума кластера, так
как в конфигурации используется один главный узел, нужно указать 1;
Примечание
В кластере должно использоваться нечётное число главных узлов, например, 1, 3, 5. В этом параметре используется число, равное n/2 +1, где n - количество главных узлов.
node.master: true - назначает экземпляр
Elasticsearch главным узлом;
node.data: false - параметр указывает,
что узел не будет хранить данные.
На 3 серверах, содержащих узлы Elasticsearch с данными, должны быть указаны такие параметры:
cluster.name: elastic_cluster
node.name: имя_узла
network.host: ip_адрес_данного_узла
discovery.zen.ping.unicast.hosts: ["192.168.4.0",
"192.168.0.155", "192.168.2.158", "192.168.2.111"]
discovery.zen.minimum_master_nodes: 1
node.master: false - указать, что узел не
является главным;
node.data: true - узел будет хранить
данные;
Для применения изменений нужно перезапустить Elasticsearch на всех нодах.
Проверить состояние узлов можно так:
# curl 'http://192.168.2.158:9200/_cat/nodes?v' ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name 192.168.2.111 41 98 29 1.50 1.41 1.31 mi * elastic_master 192.168.4.0 31 99 15 2.58 2.36 2.19 di - cassel1 192.168.0.155 26 99 15 2.58 2.36 2.19 di - cassel2 192.168.2.158 16 98 28 1.50 1.41 1.31 di - cassel3
Проверить состояние кластера:
# curl 'http://192.168.2.158:9200/_cluster/health?pretty'
{
"cluster_name" : "elastic_cluster",
"status" : "green",
"timed_out" : false,
"number_of_nodes" : 4,
"number_of_data_nodes" : 3,
"active_primary_shards" : 340,
"active_shards" : 1020,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 0,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 100.0
}
Статус кластера определяется на уровне шардов (фрагментов). Возможные статусы:
green- все фрагменты доступны;yellow- основной фрагмент размещён, но некоторые реплики фрагментов пока нет;red- часть фрагментов недоступна.
Примечание
Каждый документ хранится в одном основном фрагменте (shard). Когда документ индексируется, он сперва индексируется на основном фрагменте, а затем на всех его копиях (replicas).
Настройки на сервере Synergy производятся в конфигурационных файлах /opt/synergy/jboss/standalone/configuration/arta/jcr/jcr-cassandra.xml
и /opt/synergy/jboss/standalone/configuration/arta/jcr/ss4c-cassandra.xml.
В них следует указать ip-адреса всех нод Cassandra, в hostName добавить ip одной из нод и выбрать
уровень согласованности:
<configuration>
<nodes>
<node>
<host>192.168.4.0</host>
<port>9042</port>
</node>
</nodes>
<nodes>
<node>
<host>192.168.0.155</host>
<port>9042</port>
</node>
</nodes>
<nodes>
<node>
<host>192.168.2.158</host>
<port>9042</port>
</node>
</nodes>
<hostName>192.168.4.0</hostName>
...
<consistency-level>QUORUM</consistency-level>
</configuration>
Выбранный в данном случае уровень QUORUM
означает, что координатор кластера дожидается подтверждения записи от более
чем половины узлов, в описываемой конфигурации от 2. Уровни согласованности
можно подробнее изучить в официальной
документации.
Нужно также проверить, что в standalone-onesynergy.xml в секции resource-adapters отсутствуют либо
закомментированы строки, относящие к хранилищу Jackrabbit
Для применения изменений Wildfly/ JBoss должен быть перезапущен.
На серверах, содержащих ноды Cassandra, нужно указать следующие параметры в
/etc/cassandra/cassandra.yaml:
cluster_name: 'Synergy Cluster' - имя
кластера Cassandra;
listen_address: ip-адрес_узла - для
каждого узла указать его ip;
rpc_address: ip-адрес_узла - для каждого
узла указать его ip;
seed_provider:
- class_name: org.apache.cassandra.locator.SimpleSeedProvider
parameters:
- seeds: "192.168.4.0, 192.168.0.155" - перечислить ip-адреса раздающих узлов кластера. Не нужно делать все узлы кластера раздающими.
Более подробно настройка параметров для промышленного развёртывания описана в соответствующем разделе.
Затем нужно перезапустить Cassandra на всех серверах кластера. Состояние кластера можно проверить так:
# nodetool status Datacenter: datacenter1 ======================= Status=Up/Down |/ State=Normal/Leaving/Joining/Moving -- Address Load Tokens Owns (effective) Host ID Rack UN 192.168.0.155 250.21 MB 256 100.0% 35c9844a-ae5e-429a-bff0-4a3b9c29b8c3 rack1 UN 192.168.2.158 250.3 MB 256 100.0% 21b89eea-9779-46d5-9ac8-7096f03764a7 rack1 UN 192.168.4.0 250.24 MB 256 100.0% ecf9e4a8-4500-4462-aeb8-31f33c1c7bfb rack1