Генерация индексов элементов хранилища - файлов и документов - осуществляется в разделе «Управление индексом файлов»:
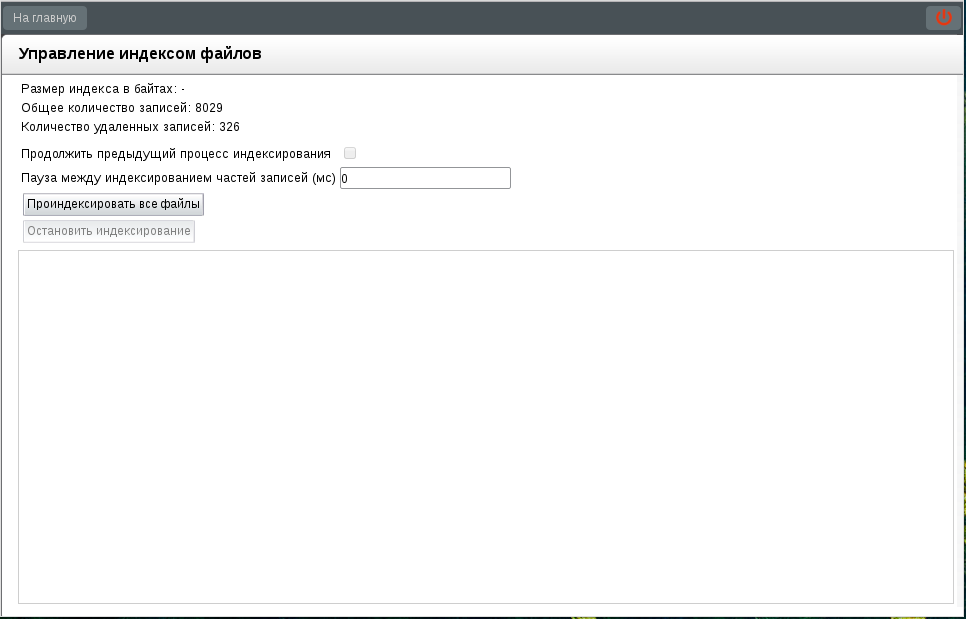
Окно «Управление индексом данных форм» содержит текущую статистику состояния данных, параметры и кнопки запуска и остановки индексирования, а также панель информации.
Статистика состояния данных
Размер индекса в байтах: при использовании Lucene (устанавливается по умолчанию) отображается прочерк «-»; при использовании Elasticsearch - текущий размер индекса.
Общее количество записей: общее количество файлов.
Количество удаленных записей: количество индексов, удаленных при изменении индексируемых данных.
Запуск и остановка индексирования
Продолжить предыдущий процесс индексирования: флаг, позволяющий продолжить ранее запущенный и остановленный процесс индексирования.
Если ранее индексирование не осуществлялось, или нет ранее запущенного и остановленного процесса, флаг недоступен.
Если последний процесс индексирования был остановлен, то рядом с флагом указан номер позиции, с которой продолжится индексирование.
Если последний процесс индексирования был остановлен, а флаг отключен, то процесс индексирования начнется заново.
Пауза между индексированием часлей записей (мс): числовое поле ввода, в котором указывается время необходимой паузы в процессе индексирования. Одной «частью» считается индексирование 200 документов.
Процесс запускается по нажатию на кнопку «Проиндексировать все файлы». Система запрашивает подтверждение действия:
«Вы действительно хотите проиндексировать все записи?»
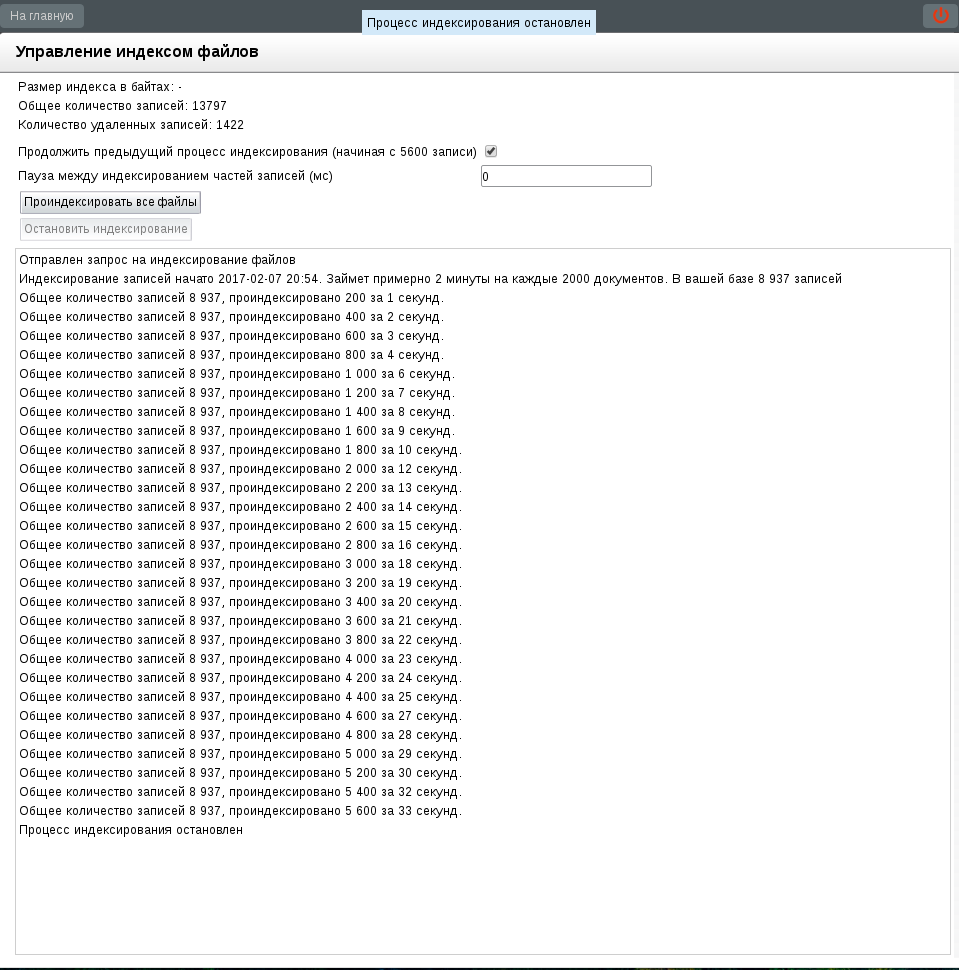
Если пользователь подтверждает действие, процесс индексирования начинается. При этом в панели информации отображается сведения о процессе индексирования каждой части в формате:
«Отправлен запрос на индексирование файлов»
«Индексирование записей начато %ГГГГ-ММ-ДД ЧЧ:ММ%. Займет примерно 2 минуты на каждые 2000 документов. В вашей базе %общее_количество_записей% записей.»
«Общее количество записей %общее_количество_записей%, проиндексировано %количество_проиндексированных_записей% за %ss% секунд»
…
«Общее количество записей %общее_количество_записей%, проиндексировано %количество_проиндексированных_записей% за %ss% секунд»
В случае, если в процессе индексирования очередной части возникли ошибки, то их текст будет отображен в отдельном сообщении об ошибке. При этом индексирование будет продолжено.
Процесс останавливается в двух случаях:
Ручная остановка - по нажатию на кнопку «Остановить индексирование». При этом в панели информации выводится сообщение:
«Процесс индексирования остановлен»
Номер позиции, на которой процесс был остановлен, запоминается, и в дальнейшем индексирование можно продолжить с этой позиции либо начать заново.
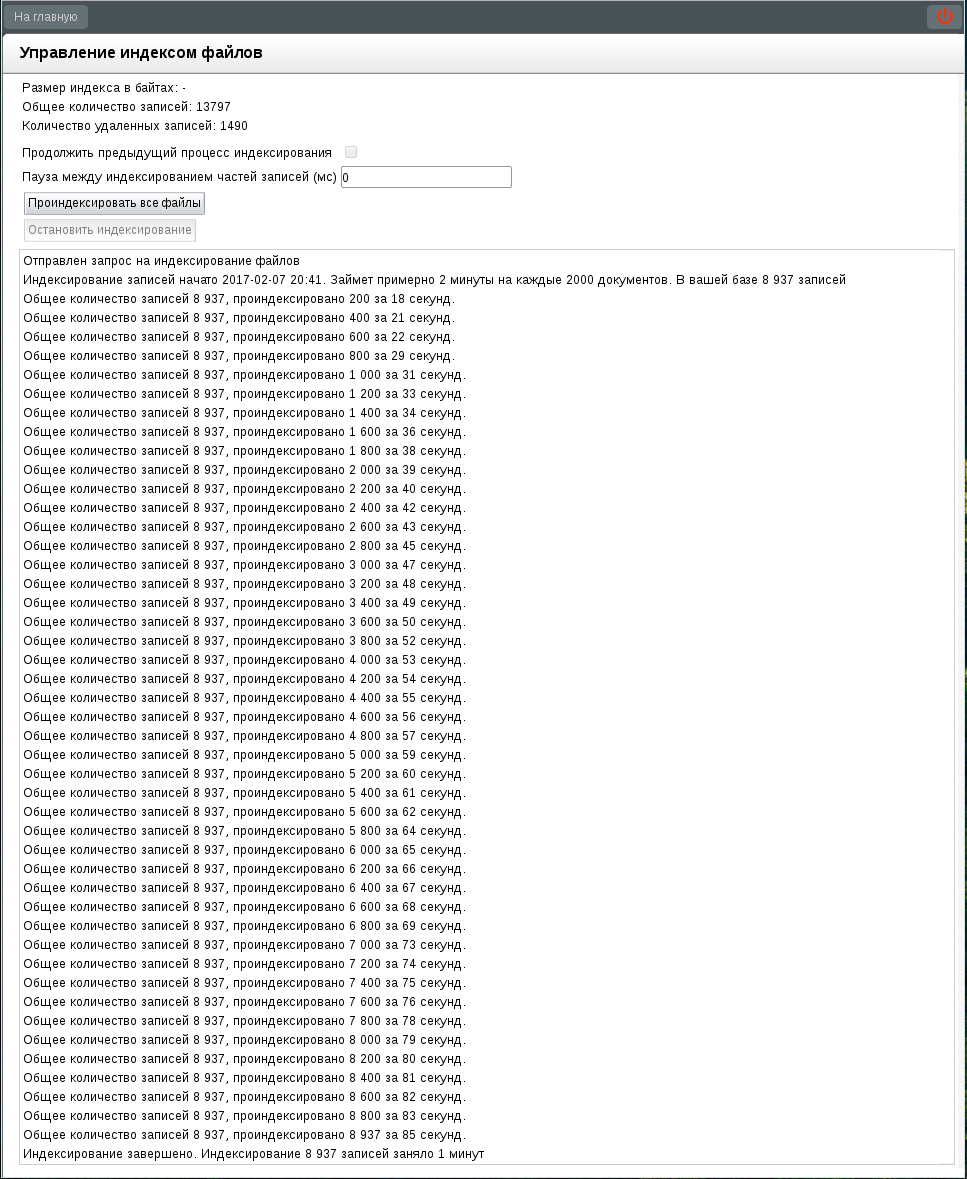
Все данные проиндексированы - процесс завершается самостоятельно. При этом в панели информации выводится сообщение:
«Индексирование завершено. Индексирование %общее_количество_записей% записей заняло %M% минут»
Помимо панели информации, сообщения о прогрессе индексирования выводятся как уведомления.
Переключение индексаторов осуществляется посредством конфигурационных файлов:
Индекс документов:
arta/esb/docIndex.xmlИндекс хранилища:
arta/esb/fileIndex.xml
Примечание:
При переключении реализации индекса необходимо провести полную переиндексацию данных.
Настройки индексирования файлов и документов указываются в файле
arta/elasticConfiguration.xml.
Документы:
Каждый документ в индексе содержит как минимум следующие поля:
| Имя поля в индексе | Тип поля | Хранимые данные в терминах Synergy |
|---|---|---|
|
documentId |
keyword |
идентификатор документа |
|
docID |
keyword |
идентификатор РКК |
|
createDate |
keyword |
дата создания документа (в мс) |
|
modified |
keyword |
дата изменения документа (в мс) |
|
createDate_num |
long |
дата создания документа (в мс) |
|
number |
text |
номер документа |
|
registered |
long |
дата регистрации документа (в мс) |
|
subject |
text |
краткое содержание |
|
correspondent |
text |
корреспондент |
|
correspondent_org |
text |
корреспондент (орг.) |
|
base_number |
text |
номер исходящего документа |
|
base_date |
long |
дата дата исходящего документа (в мс) |
|
reg_date |
long |
дата регистрации документа (в мc) |
|
doc_type |
keyword |
идентификатор типа документа |
|
doctypename |
text |
название типа документа |
|
duration |
long |
длительность (рабочих дней) |
|
author |
keyword |
ID автора документа |
|
authorname |
text |
имя автора документа |
|
reg_user |
keyword |
ID пользователя, зарегистрировавшего документ |
|
regusername |
text |
имя пользователя, зарегистрировавшего документ |
|
counter_number |
long |
склеенная числовая часть номера документа |
|
control |
boolean |
признак контрольного документа |
|
defective |
boolean |
признак бракованного документа |
|
writtenoff |
boolean |
признак списанного в дело документа |
|
active |
boolean |
признак наличия работ по документу |
|
late |
boolean |
признак просроченного документа |
|
register |
keyword |
ID журнала, в котором расположен документ |
|
docfile |
keyword |
ID дела, к которому относится документ |
|
registry |
keyword |
ID реестра, к которому относится документ |
|
counter |
long |
числовая часть счетчика документа |
|
ui |
keyword |
символьный суффикс номер документа |
|
uinumber |
long |
числовая часть номера документа |
|
status_sort |
long |
код статуса документа |
|
sent_date_* |
long |
дата отправки документа пользователем (в мс) |
|
read_date_* |
long |
дата прочтения документа пользователем (в мс) |
|
sending_date_* |
long |
дата получения документа пользователем (в мс) |
|
lastdate_* |
long |
максимум между датой прочтения и отправки документа пользователем (в мс) |
|
read_* |
boolean |
признак того, что документ прочитан |
|
hidden_* |
boolean |
признак того, что документ скрыт от пользователя |
|
all |
keyword |
список ID пользователей, у которых документ должен быть в фильтре «Все документы» |
|
sent |
keyword |
список ID пользователей, у которых документ должен быть в фильтре «Отправленные» |
|
received |
keyword |
список ID пользователей, у которых документ должен быть в фильтре «Полученные» |
|
mine |
keyword |
список ID пользователей, у которых документ должен быть в фильтре «Мои» |
counter<N>- поле, содержащее числовую часть счетчика документа.<N>- порядковый номер части, от 1 до 5;ui<N>- поле, содержащее суффикс номера документа (не числовой), расположенный между числовыми частями номера.<N>- порядковый номер суффикса, от 1 до 5;uinumber<N>- поле, содержащее числовую часть номера документа, расположенную между символьными суффиксами.<N>- порядковый номер части, от 1 до 5;в полях с постфиксом
_*вместо * используется ID пользователя.поле
docIDдолжно загружаться в индекс в том случае, если у документа есть сохраненная РКК.
Для следующих полей используется русскоязычный анализатор текста:
correspondentcorrespondent_orgdoctypenameauthornameregusernameusernamenumberbase_numberformvalues
subject
base_number
formvalues
Кроме того, для полей number,
subject, base_number и
formvalues дополнительно используется
параметр веса.
Файлы и ярлыки:
Каждый документ в индексе содержит как минимум следующие поля:
| Имя поля в индексе | Тип поля | Хранимые данные в терминах Synergy |
|---|---|---|
|
NODE_ID |
keyword |
ID файла |
|
DOC_CREATED |
long |
дата создания файла (в мс) |
|
DOC_AUTHOR_ID |
keyword |
ID пользователя, создавшего файл |
|
PARENT_NODE_ID |
keyword |
ID родительской папки файла |
|
PATH |
keyword |
расположение файла |
|
DOC_FILENAME |
text |
название файла |
|
NODE_NAME |
text |
название файла |
|
DOC_COMPANION_ID |
keyword |
тип сущности, к которой принадлежит файл (документ, заметка, план, личное дело) |
|
DOC_CATEGORIES |
long |
список категорий, к которым принадлежит файл |
|
DOC_EXPIRE_DATE |
long |
срок действия версии файла (в мс) |
|
DOC_PUBLISH_DATE |
long |
дата публикации файла (в мс) |
|
DOC_SIZE |
long |
размер файла (в байтах) |
|
DOC_COMPANION_MEMBERS |
keyword |
массив ID пользователей, имеющих доступ к файлу согласно их правам на COMPANION_ID |
|
DOC_MIME_TYPE |
keyword |
название типа файла |
|
ANCESTORS |
keyword |
список идентификаторов родительских папок |
|
DOC_TITLE |
text |
название файла |
|
DOC_CONTENT |
text |
текст документа (если возможно выделить непосредственно текст или служебную информацию для данного типа файла) |
|
DOC_COMMENTS |
text |
комментарий к текущей версии файла |
|
DOC_METADATA |
text |
склеенные данные свойств файла |
|
READS_COUNT |
long |
количество открытий файла |
Помимо описанного набора полей, для каждого свойства файла с
кодом optionID создается поле с именем
aiDocumentCompanionField<optionID>.
Для следующих полей используется русскоязычный анализатор текста:
DOC_CONTENT
DOC_METADATA
DOC_FILENAME
NODE_NAME
DOC_TITLE
DOC_COMMENTS
Кроме того, для полей DOC_FILENAME,
NODE_NAME, DOC_TITLE,
DOC_COMMENTS дополнительно используется
параметр веса.
Примечания:
Описанный набор полей применяется для индексации как файлов, так и ярлыков. Часть полей в индексе может быть пустой, если невозможно выделить соответствующее свойство файла (например, список свойств и категорий для ярлыка).
Для всех анализируемых текстовых полей в индексе файлов создаются дополнительные текстовые анализируемые поля для каждой используемой локали.