Хранилище Cassandra предназначено для обработки нагрузки данных больших
объемов между множеством узлов без отказа системы. Его архитектура основана
на том, что сбои в системе и аппаратных средствах возможны, и они
происходят. Данное хранилище решает проблему сбоев, используя одноранговую
(децентрализованную) распределенную систему между однородными узлами, где
данные распределены между всеми узлами кластера. Все узлы обмениваются
информацией по кластеру каждую секунду. Последовательно записанные логи
изменений в каждом узле фиксируют активность записи для обеспечения
долговечности данных. Далее данные индексируются и записываются в элемент
памяти, который называется Memtable,
очень похожий на кэш обратной записи. Когда этот элемент памяти полон,
данные записываются на диск в файл данных SSTable. Все записи автоматически разделяются и
копируются по всему кластеру. Во время процесса, который назвается
уплотнение (compaction), хранилище
периодически объединяет файлы SSTable,
отбрасывая устаревшую информацию и индикаторы об удалении данных.
Cassandra - это строчно-ориентированная база данных. Ее архитектура
позволяет каждому авторизованному пользователю подключаться к произвольному
узлу любого дата-центра и получать доступ к данным, используя язык CQL. Для
простоты использования язык CQL имеет синтаксис аналогичный языку SQL. С
точки зрения языка CQL база данных состоит из таблиц. Обычно кластер имеет
одно пространство ключей
(keyspace) для каждого приложения. Разработчики могут
получить доступ к CQL через cqlsh, а
также с помощью драйверов для языков приложений.
Запросы клиента на чтение и запись могут быть отправлены любому узлу в кластере. Когда клиент подключается к узлу с запросом, этот узел служит в качестве координатора для этой конкретной операции клиента. Координатор выступает в роли прокси между приложением клиента и узлами, в которых находятся данные запроса. Координатор определяет, какие узлы в цепи должны получить запрос, в зависимости от настроек кластера.
Узел (Node) - место хранения данных. Это основной элемент хранилища Cassandra.
Дата-центр (Data center) - набор связанных между собой узлов. Он может быть физическим либо виртуальным центром. Разные рабочие нагрузки должны использовать отдельные дата-центры (физические либо виртуальные вне зависимости от типа). Репликация устанавливается дата-центром. Использование отдельных центров предотвращает влияние других нагрузок на транзакции хранилища и позволяет хранить запросы рядом для уменьшения задержки времени. В зависимости от коэффициента репликации данные могут быть синхронизированы в множестве дата-центрах. В любом случае, дата-центры никогда не занимают физическое местоположение.
Кластер (Cluster). Кластер состоит из одного или нескольких дата-центров. Он может иметь некое физическое местоположение.
Логи изменений (Commit log). Все данные вначале записываются в логи изменений для обеспечения их долговечности. После того, как все данные будут переданы в
SSTables, они могут быть заархивированы, удалены либо переработаны.Таблица (Table) - набор упорядоченных столбцов, использующихся по строкам. Строка содержит столбцы и первичный ключ. Первая часть ключа это название столбца.
Отсортированная строковая таблица
SSTable(SSTable - sorted string table) - неизменяемый файл данных, к которому хранилище периодически добавляет информацию из таблицMemtable. В таблицуSSTableвозможно только добавлять данные. Они хранятся в последовательном порядке на диске и поддерживаются для каждой таблицы хранилища Cassandra.
Госсип (Gossip) - одноранговый протокол связи, который используется для обнаружения и передачи информации о местоположении и состоянии других узлов в кластере хранилища Cassandra. Данная информация также сохраняется локально на каждом узле для использования сразу после перезагрузки узла.
Партиционер (Partitioner) - определяет, какой узел получит первую копию фрагмента данных и как распределить другие копии между остальными узлами кластера. Каждая строка данных имеет уникальный идентификатор в виде первичного ключа, который может соответствовать ее ключу раздела, но при этом может содержать иные кластерные столбцы. Партиционер - это хэш-функция, которая извлекает значение маркера из первичного ключа строки. Партиционер использует значение маркера для определения того, какие узлы кластера получают копии этой строки. Партиционер
Murmur3Partitioner- это стандартная стратегия разделения для новых кластеров хранилища Cassandra, а также верный вариант для новых кластеров практически во всех случаях.Для каждого узла необходимо установить партиционер и присвоить значение параметру
num_tokens. Значение этого параметра зависит от аппаратных возможностей системы. Если не используются виртуальные узлы (vnodes), вместоnum_tokensнужно присваивать значение параметруinitial_token.Коэффициент репликации (Replication factor) - общее количество копий по всему кластеру. Коэффициент репликации, равный 1, означает, что на одном узле имеется только одна копия каждой строки. Коэффициент репликации, равный 2, означает, что имеется две копии каждой строки, но эти копии находятся на разных узлах. Все копии одинаково важны, нет первичной либо главной копии. Необходимо определять коэффициент репликкации для каждого дата-центра. Как правило, желательно устанавливать значение коэффициента больше чем один, но не более чем количество узлов в кластере.
Стратегия размещения реплики (Replica placement strategy). Хранилище Cassandra хранит копии данных на множестве узлов для обеспечения надежности и отказоустойчивости. Стратегия репликации определяет, на каких узлах необходимо размещать копии. Первая реплика данных это просто первая копия данных, она не уникальна. Для большинства случаев настоятельно рекомендуется использовать
NetworkTopologyStrategy, потому что данная стратегия позволяет легко увеличивать количество дата-центров при необходимости дальнейшего расширения.При создании пространства ключей необходимо определить стратегию размещения реплики и необходимое количество копий.
Снитч (Snitch) - определяет группы машин в дата-центрах и на стойках (топологиях), которые используются стратегией репликации для размещения копий.
Настраивать снитч необходимо при создании кластера. Все снитчи используют динамический слой, который контролирует производительность и выбирает лучшую копию для чтения. Он включен по умолчанию и рекомендован для использования в большинстве сборок. Граничные значения динамических снитчей настраиваются для каждого узла в конфигурационном файле
cassandra.yaml.Использующийся по умолчанию
SimpleSnitchне распознает дата-центры и стойки информации. Его рекомендуется использовать для развертываний с одним дата-центром или для одиночной зоны в общедоступных облаках.GossipingPropertyFileSnitchрекомендован для промышленной эксплуатации. Он определяет узел дата-центра и стойку, и использует госсипы для распространения данной информации другим узлам.Файл конфигурации
cassandra.yaml- основной конфигурационный файл для установки свойств инициализации кластера, кэширования параметров таблиц, свойств настройки и использования ресурсов, настроек тайм-аута, клиентских подключений, резервного копирования и безопасности. По умолчанию узел настроен для хранения данных, которыми он управляет в директории, установленной в файлеcassandra.yaml(/var/lib/cassandraпри установке из пакета).В развертываниях промышленного кластера можно изменить директорию
commitlog-directoryна другой диск изdata_file_directories.Свойства таблицы системного ключевого пространства (System keyspace table properties). Для установки атрибутов конфигурации хранилища на табличном уровне либо на уровне ключевого пространства программно или с использованим клиентского приложения, такого как CQL.
Описаны сведения для развертывания кластера хранилища Cassandra с одним дата-центром. Если кластер не создан, рекомендуется изучить статьи “Cassandra and DataStax Enterprise Essentials” или “10 Minute Cassandra Walkthrough”.
Для хранилища Cassandra термин дата-центр означает группу узлов. Дата-центр, как и группа репликации, означает группу узлов, настроенных совместно для обеспечения свойства репликаци.
Каждый узел должен быть правильно настроен перед запуском кластера. Необходимо определить или выполнить следующие действия перед началом работы:
Хорошо понимать, как работает Cassandra. Рекомендуется изучить как минимум следующие статьи:
Установить Cassandra на каждый узел.
Указать имя для кластера.
Получить IP-адрес для каждого узла.
Определить узлы, которые будут раздающими (seed nodes). Не нужно делать все узлы раздающими. Рекомендуется изучить протокол взаимодействия узлов (Internode communications (gossip)).
Определить снитч и стратегию репликации. Для промышленных развертываний рекомендуются
GossipingPropertyFileSnitchиNetworkTopologyStrategy.
При использовании нескольких дата-центров требуется определить правила именования для каждого дата-центра и стойки (rack), например:
DC1, DC2;
100, 200;
RAC1, RAC2;
R101, R102
Будьте внимательны при указании имени: переименование дата-центра невозможно.
Другие возможные настройки конфигурации описаны в конфигурационном файле
cassandra.yamlи в файле свойствcassandra-rackdc.properties
В примере описана установка кластера из 6 узлов, охватывающего 2 стойки в
одном дата-центре. Каждый узел настоен с использованием GossipingPropertyFileSnitch и 256
виртуальных узлов (vnodes).
Хранилище Cassandra устанавливается с помощью команды:
# aptitude install arta-synergy-jcr4c
После установки Cassandra проверить ее статус можно командой:
# service cassandra status
Обратите внимание: по умолчанию при установке хранилища Cassandra взамен Jackrabbit оно не содержит никаких данных - в том числе тех, которые ранее содержались в Jackrabbit. Миграцию данных необходимо выполнять специальным образом.
Предполагается, что Cassandra устанавливается на следующие узлы:
node0 110.82.155.0 (seed1) node1 110.82.155.1 node2 110.82.155.2 node3 110.82.156.3 (seed2) node4 110.82.156.4 node5 110.82.156.5
Примечание: рекомендуется делать более одного seed узла для одного дата-центра
Если на кластере запущен брандмауэр, необходимо открыть определенный порт для коммуникации между узлами. Подробнее об этом в статье Configuring firewall port access
Если Cassanra запущена, требуется остановить сервер и очистить данные: Выполните удаление для кластера по умолчанию
cluster_name(Test Cluster) для системной таблицы. Все узлы должны использовать одно имя кластера.Пакетная установка:
остановка Cassandra:
$ sudo service cassandra stop
очистка данных:
$ sudo rm -rf /var/lib/cassandra/data/system/*
Установка tar-архива:
остановка Cassandra:
$ ps auwx | grep cassandra $ sudo kill pid
очистка данных:
$ sudo rm -rf /var/lib/cassandra/data/system/*
Установите свойства в файле
cassandra.yamlдля каждого узла:Примечание: после внесения любых изменений в файл
cassandra.yamlнеобходимо перезапускать узел для применения этих изменений.Параметры для установки:
num_tokens: рекомендуемое значение: 256
seeds: внутренний IP-адрес для каждого раздающего узла.
Раздающие узлы не проходят инициализацию, которая выполняется для каждого нового узла, присоединяемого к существующему кластеру. Для новых кластеров процесс инициализации для раздающих узлов пропускается.
listen_address.
Если параметр не установлен, Cassandra запросит в системе локальный адрес, связанный с именем хоста. В некоторых случаях Cassandra не дает правильный адрес, и необходимо настроить параметрlisten_address.
endpoint_snitch: имя снитча.
Если снитчи были изменены, то рекомендуется изучить статью “Замена снитчей” (Switching snitches).
auto_bootstrap: false Добавлять этот параметр необходимо только при запуске нового кластера, не содержащего данных.
Примечание: если узлы в кластере идентичны в смысле дискового пространства, распределенных библиотек и т. д., можно использовать одинаковые копии файла
cassandra.yamlдля всех них.
Пример:
cluster_name: 'MyCassandraCluster'
num_tokens: 256
seed_provider:
- class_name: org.apache.cassandra.locator.SimpleSeedProvider
parameters:
- seeds: "110.82.155.0,110.82.155.3"
listen_address:
rpc_address: 0.0.0.0
endpoint_snitch: GossipingPropertyFileSnitch
В файле
cassandra-rackdc.propertiesдля дата-центра и стоек требуется назначить имена, определенные перед началом работы. Например:# indicate the rack and dc for this node dc=DC1 rack=RAC1
После установки и настройки Cassandra на всех узлах, сначала по одному запустите seed-узлы, потом запустите остальные узлы.
Пакетная установка:
$ sudo service cassandra start
Установка tar-архива:
$ cd install_location $ bin/cassandra
Примечание: если узел перезапустился из-за автоматического перезапуска, то сначала требуется остановить узел и очистить каталоги данных, как описано выше.
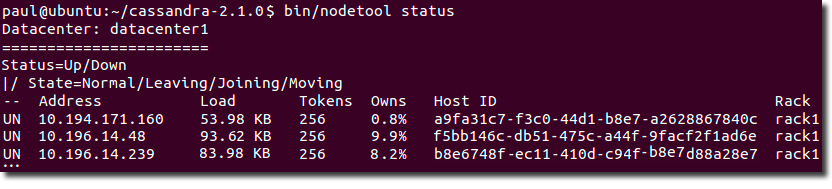
Для проверки того, что цепь запущена и работает, выполните:
для пакетной установки:
$ nodetool status
для установки из tar-архива:
$ cd install_location $ bin/nodetool status
Каждый узел должен быть указан в списке, и его статус должен быть UN (Up Normal): (илл. “Проверка работы кластера”).
Если хранилище Cassandra устанавливается на замену стандартному хранилищу Jackrabbit, уже содержащему данные, необходимо предварительно выполнить миграцию данных.
Synergy поддерживает два типа миграции: стандартную и кастомную.
Стандартная миграция предназначена для миграции всех версий документов и последних версий файлов.
Стандартная миграция может быть “полной” или “ленивой”:
полная миграция требует выполнения на остановленном jboss, работа пользователей в Synergy в это время невозможна;
ленивая миграция выполняется на запущенном jboss; работа пользователей в Synergy, хоть и замедляется, но может быть в продолжена в штатном режиме.
Процедура выполнения полной миграции:
остановить jboss:
# /etc/init.d/arta-synergy-jboss stopустановить пакет мигратора:
# aptitude install arta-synergy-jcrmigratorзапустить собственно миграцию:
# /opt/synergy/utils/jcrmigrator/jcrmigrator migrateпосле завершения миграции установить основной пакет Хранилища
arta-synergy-jcr4c:# aptitude install arta-synergy-jcr4cзапустить jboss:
# /etc/init.d/arta-synergy-jboss start
Выполнение ленивой миграции:
остановить jboss:
# /etc/init.d/arta-synergy-jboss stopустановить пакет мигратора:
# aptitude install arta-synergy-jcrmigratorзапустить миграцию каркаса хранилища:
# /opt/synergy/utils/jcrmigrator/jcrmigrator prepareВыполнение команды занимает примерно 1 минуту на 200 документов.
запустить jboss:
# /etc/init.d/arta-synergy-jboss startПри старте jboss версии документов начинают в “ленивом” режиме мигрировать из одного хранилища в другое. При каждом старте jboss выполняется вычисление количества оставшихся версий документов.
Обратите внимание: до завершения миграции запуск и работа jboss будут выполняться медленнее, чем обычно.
Проверка состояния нового хранилища, подсчет количества оставшихся версий (запускается только на остановленном jboss):
# /opt/synergy/utils/jcrmigrator/jcrmigrator checkКогда
checkсообщит, что все версии успешно мигрированы, можно ставить основной пакет Хранилищаarta-synergy-jcr4c:# aptitude install arta-synergy-jcr4cЭтот пакет установит хранилище на Cassandra, которое уже будет содержать мигрировавшие документы.
Если требуется более подробный вывод хода миграции, а именно отображение документов, которые в данный момент в обработке, можно воспользоваться следующими командами:
# /opt/synergy/utils/jcrmigrator/jcrmigrator migrate_debug
# /opt/synergy/utils/jcrmigrator/jcrmigrator prepare_debug
Миграция с их помощью будет проходить так же, как при выполнении ранее
описанных команд migrate и prepare, но с большей детализацией.
Кастомная миграция предназначена для миграции последних версий неудаленных документов реестров и личных карточек пользователей.
Процедура выполнения:
остановить jboss:
# /etc/init.d/arta-synergy-jboss stopустановить пакет мигратора:
# aptitude install arta-synergy-jcrmigratorзапустить миграцию последних версий всех документов в системе (записей реестров, документов в журналах):
# /opt/synergy/utils/jcrmigrator/jcrmigrator migrate_docsПри повторном выполнении команды будет осуществляться домиграция оставшихся документов.
После завершения миграции будет выведено сообщение:Congratulations! You have fully migrated your documents storage to Cassandra.
запустить миграцию последних версий всех файлов в Хранилище Synergy (отображаемых в модуле Хранилище - Файлы):
# /opt/synergy/utils/jcrmigrator/jcrmigrator migrate_filesПри повторном выполнении команды будет осуществляться домиграция оставшихся файлов.
После завершения миграции будет выведено сообщение:Congratulations! You have fully migrated your files storage to Cassandra.
запустить миграцию последних версий карточек пользователей:
# /opt/synergy/utils/jcrmigrator/jcrmigrator migrate_cardsДля карточек пользователей также предусмотрена домиграция при повторном выполнении команды.
После завершения миграции будет выведено сообщение:Congratulations! You have fully migrated your personal cards storage to Cassandra.
запустить миграцию предыдущих версий документов, которые были мигрированы командой
migrate_docs:# /opt/synergy/utils/jcrmigrator/jcrmigrator migrate_versionsАналогично, предусмотрена домиграция при повторном запуске. После завершения миграции будет выведено сообщение:
Congratulations! You have migrated all version of documents to Cassandra.
когда будет завершена миграция всех необходимых документов, можно установить основной пакет хранилища Cassandra:
# aptitude install arta-synergy-jcr4c